Estimations, guesstimations, predictions and forecasting

Fortune Teller, by Albert Anker (1880)
“How long will this take?”
How many times have you been asked this question? Oh, come on, confess how many of those you’ve been tempted to say “Well, I can see in my crystal ball…” but finally you thought “I have no idea… but I must give an answer” or even better “I have no idea… but I remember the learnings in the Giving and Receiving Feedback training, so I must give an assertive answer”. I’ll try to help you to do that.
Needs
First, we need to understand the reason why the person is asking that question.
Sometimes she is a stakeholder who just needs to know an approximation, so she can also organise herself or help other people organise, e.g. synchronise with other teams for a marketing campaign. It can also happen that the question comes from a Product Owner to the developers while doing a refinement. Then, usually the need is giving the right priority to that work item.
Another typical situation is budgeting. Depending on the time spent in the development we can correlate a cost. It looks easy when the team is stable and you are used to do very similar tasks. In these cases, the experience of the team evaluating the risks is usually enough and t-shirt sizes or any other categorization works well. But not even with a stable team estimations are easy. The requests, the environment and the technology may not be stable, and there are other sources of variability.
If the question does not link with any of these situations, it is usually related to something more emotional, not coming from an objective observation of data. Impatience mostly. Maybe due to a long wait or to pressure coming from someone else (up in the hierarchy who is also impatient). Uncertainty can create this fear to not reaching the market fast enough.
Before reading further, take a minute to think which answer you could give in the previous situations.
Answer
In those cases you can kindly answer:
“So, it seems you don’t really need a date. If you really need a date I will give it to you, but if you don’t, experience proves that it’s much better not to rush. Listen, we are committed to do our best and as fast as we can to deliver on time and with the highest quality. To give you a date, we need to stop our work in progress and prepare that estimation for you. Do you still need that date?”
In my experience, 9 out of 10 people will answer no, but the rest will feel more comfortable than with a “I have no idea” or “Go away, I cannot give you a date”. Yes, assertive answers tend to be longer than non-assertive ones. 🙂
For those who still feel the need to have an answer although it’s not connected to an actual need, we can still kindly refuse to give a guesstimation, i.e., an estimation based on a guess. I suggest using this term to help them better understand the impact of their request. They are still stopping your work to do an activity which is not related to an actual need, and on top of that it’s just a guess which is not supported by data, i.e. just an opinion. Another impact that these requests for guesstimations can bring is that people interrupted generally feel forced to give optimistic estimations, mainly due to emergencies that are affecting the requester. So we are increasing the probabilities of giving a number that will not fit with reality, usually impacting on others because they are managing their expectations based on inaccurate information.
On the other hand, for those who really need a date, this can be the answer, assuming you are doing Kanban.
“Well, to give you a date we need to stop our work in progress and prepare the estimation for you. It is based on our capacity to be predictable and on a statistical simulation that will forecast the dates for you based on our past performance.”
I’m pretty sure some doubts have just come to your head now. “What if my team is not predictable? What if my team has no past behaviour? How the hell can a simulation give an estimation I can trust better than the team’s opinion?”. Ok, as Jack The Ripper would say: “Let’s go by parts”.
Show me the data
First, let’s look at the data we are collecting and how we can use it to see if we are predictable or not. Many teams at eDreams ODIGEO are doing Kanban and using JIRA to visualize, manage and measure their work. This way, with the help of a plugin called EazyBI, we can create some useful charts like the ones I’ll show you now.
If you see a run-chart with the tasks you are delivering and their customer lead time (the time spent by the team from the moment they decided to start working on it until the moment they deliver it), you probably will see a cloud of dots. Hopefully a lot of them because the team is producing a lot of valuable features for our customers.
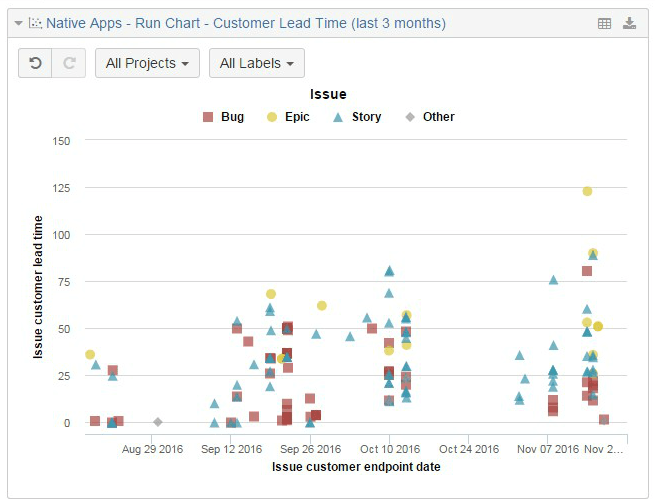
Can you see a pattern here? Yes, some empty gaps and I would say many bugs too, but we can also see that most of those tasks were finished in less than 50 days. Actually we can look at this data with a different chart.
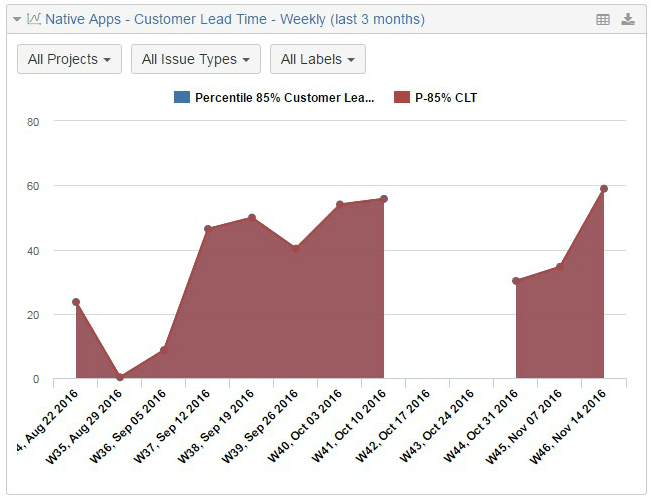
Here we can see that 85% of the tickets reaching the endpoint in the last week took 60 days or less from the moment the team started to work on them. This chart also shows those empty gaps (weeks when nothing was delivered) we already saw in the run-chart, but it also lets us see the variability of the work done by this team. If you just ignore those gaps, then you will see something more stable, around 50 days. Like in the run-chart.
I’m showing you these charts because I want you to understand the importance of stability when providing a forecast, and also to show you how we can use them to understand a team’s behaviour. In another article we can discuss how to improve behaviours by reading what the charts show. Now I will show you how you can actually answer The Big Question.
How long will this take?
This is the point where we must introduce the Monte Carlo simulations. Here you have a good article explaining this technique in more depth. The goal of this article is to show you the mechanics on how to use it to answer The Big Question.
At eDreams ODIGEO we are fostering the use of these Excel spreadsheets (created by Troy Magennis) to run the simulations for all the people asking The Big Question. Now we are using this version of the spreadsheet. It’s in Google Drive thanks to Troy and you only need to make a copy and share with your team to start collaborating.
How can you run your own forecast? Just open and save a copy of the spreadsheet. Then you can go to the tab “Forecast” and fill the data for your case.
Imagine you have a backlog with 12 stories in it, and you want to know when your 12th story will (hopefully) be finished. Then you will fill the “Start Date” with today’s date (remember: American date format, MM/DD/YYYY) and answer 12 for the question “2. How many stories are remaining to be completed?” in both fields (“Lowest guess”/”Highest guess”).
Let’s forget about the rest of the fields for now and go to the section “4. Throughput”. In this point you will need to know how many stories you are delivering each week. That metric is known as throughput. Then fill the tab “Throughput samples”. The more historical data you have, the better, although you can be surprised by how few samples you need in order to have an answer with enough accuracy.
If you don’t have that historical data, you still can do your forecast by selecting “Estimate”. Of course, it will be based on a guess. The spreadsheet allows you to give a range to simulate the variability you are experiencing.
At the right side, in the section “Results”, you will find a table with dates of completion (number of weeks) of the last item in your backlog (remember, that 12th story) and the probability you can consider it will be delivered.
I suggest you also have a look at this article about burn-up charts. It may help you to draw your forecasts in a chart. Try to draw, in the same chart, the same forecast for different probabilities.
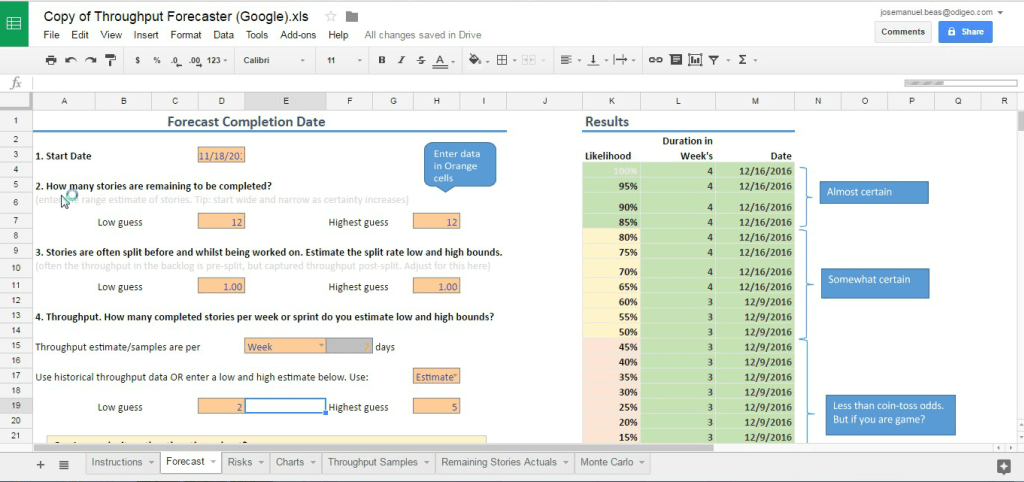
Click on the image to see the details. There are many more options, but this article is too long already. If you are interested in going deeper, please use the comments below. 🙂
Just a final thought though. “Past Performance Does Not Guarantee Future Results”. Predictability is the key. If you work to have a stable flow, i.e. a throughput with small variations and reliable data, then your forecasts will be very accurate.
I hope this article has been useful for you in order to answer The Big Question from a different perspective. I would love to know your experiences using forecast instead of estimations. And if you are curious about that “Giving and Receiving Feedback training” that I mentioned at the beginning, please drop me a line in the comments below and I’ll ask my friends in the Learning and Development department to write an article about it.
Really interesting article!
Thank you very much for sharing Jose!
Thank you, Dominique. Please, if you do some forecasting, we’d love to know about your experience. 🙂
Great article, thank you.
I’ll come back when I try it.
Thank you, Angel. Yes, it would be great knowing about your experience.